International Conference on Machine Learning(ICML)是机器学习与人工智能领域的国际顶级学术会议,也是中国计算机学会CCF推荐的A类会议。ICML 2026将于2026年7月6日至11日在韩国首尔举办。厦门大学多媒体可信感知与高效计算教育部重点实验室共有17篇论文被录用,录用论文简要介绍如下:(按第一作者姓氏拼音排序)
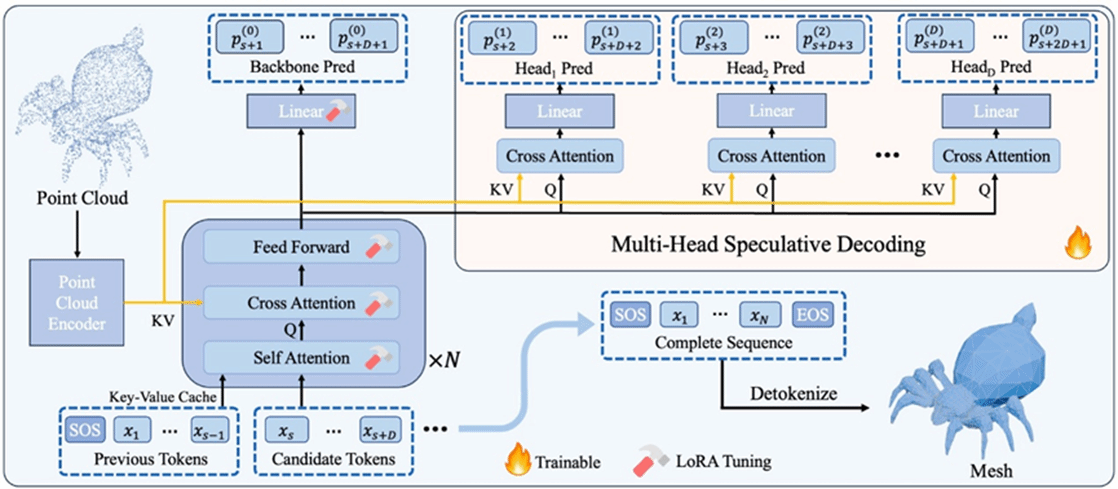
1.XSpecMesh: Quality-Preserving Auto-Regressive Mesh Generation Acceleration via Multi-Head Speculative Decoding
当前的自回归模型已经能够生成高质量、拓扑结构精确的网格;然而,在推理过程中,它们需要进行数千次甚至上万次的 next-token 预测,因此会带来显著的延迟。本文提出了XSpecMesh,这是一种在保持生成质量的前提下,加速自回归网格生成模型的方法。XSpecMesh 采用轻量级的多头推测解码方案,在一次前向传播中并行预测多个 token,从而提升推理速度。论文进一步提出了一种验证与重采样策略:由骨干模型对每个预测出的 token 进行验证,并对未达到质量标准的token 重新采样。此外,还提出了一种蒸馏策略,通过从骨干模型中进行知识蒸馏来训练这些轻量级解码头,促使它们的预测分布更加一致,从而提高推测预测的成功率。大量实验表明,本文方法在不牺牲生成质量的情况下实现了推理加速。
该论文共同第一作者是在厦门大学人工智能研究院2024级硕士生陈典和2023级博士生曲延松,通讯作者是张声传副教授,由2023级博士生李新阳、李明(浪潮科技)共同合作完成。
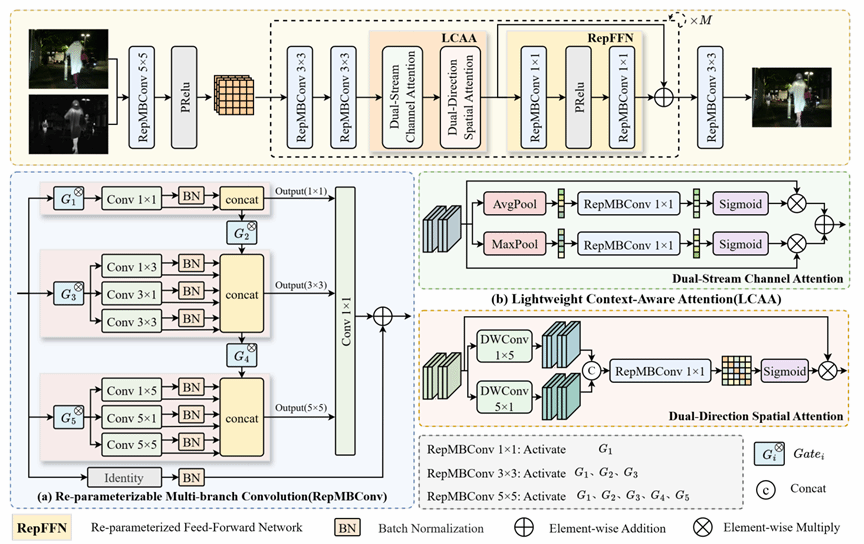
2.MobileFusion: Mobile-Friendly Infrared and Visible Image Fusion via Structural Re-parameterization
现有红外与可见光图像融合方法往往依赖复杂网络结构、自注意力机制或迭代式扩散生成过程,导致计算开销大、参数规模高,难以满足边缘设备对实时推理和低资源占用的严格要求。为此,本文提出MobileFusion,一种面向资源受限场景的极轻量红外与可见光图像融合框架,能够在仅约4K参数规模下实现高质量、实时的图像融合。其核心在于融合导向的结构重参数化多分支异构卷积模块:训练阶段,通过多尺度、多方向的异构卷积分支以及通道聚合机制,增强红外热辐射信息与可见光纹理细节之间的跨模态交互;推理阶段,则通过数学等价转换将多分支结构折叠为紧凑的单路径卷积算子,从而显著降低推理延迟和内存访问开销。进一步地,MobileFusion引入轻量上下文感知注意力与重参数化前馈网络,在极低参数量下提升局部结构和全局上下文感知能力。实验表明,MobileFusion取得了与最先进模型相当的性能,且在边缘端实现了实时推理,为图像融合技术在现实场景中的应用提供了高效可行的方案。
该论文的第一作者是厦门大学人工智能研究院2024级硕士生段雨发,通讯作者是涂晓彤教授。由2024级硕士生黄佳凌、蔡伟民、2022级博士生王莹莹、丁兴号教授共同合作完成。
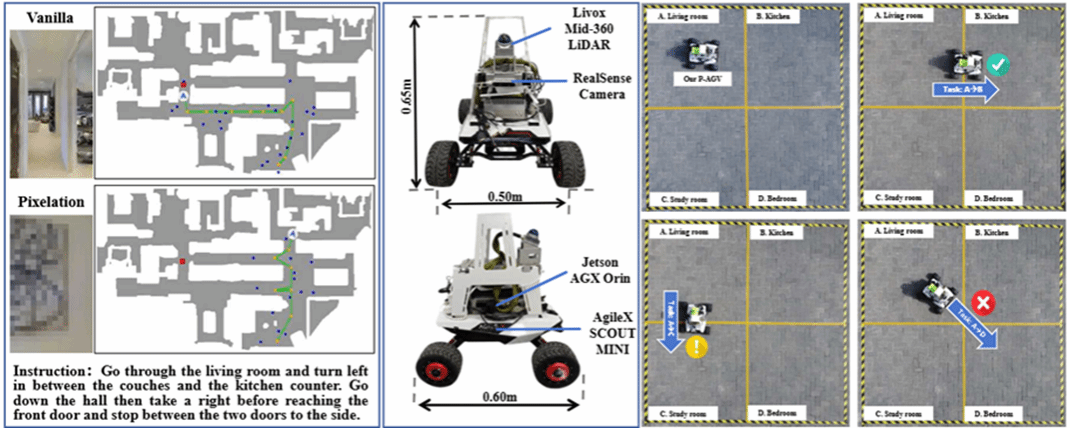
3.Position: Embodied AI Requires a Privacy-Utility Trade-off
本文讨论了具身智能在家庭、医疗、养老等真实敏感场景中部署时面临的“隐私-效用”权衡问题。论文指出,现有具身智能方法通常分别优化“指令理解、环境感知、动作规划、物理交互”等独立阶段,却忽视了隐私风险在系统生命周期中的跨阶段耦合传播,导致局部隐私保护措施难以应对真实部署中的不可逆隐私泄露。为此,本文提出具身智能安全隐私协同框架 SPINE,将隐私视为贯穿具身智能全生命周期的动态控制信号,而非单一模块的局部补丁。SPINE 构建了从 L1 Public 到 L4 Restricted 的多级隐私分类矩阵,并根据不同场景的敏感程度动态调节感知、规划与交互策略,在保证任务可用性的同时降低隐私暴露风险。论文进一步通过仿真导航任务与真实 AGV 平台实验,展示了隐私约束如何影响导航成功率与路径效率,揭示了具身智能系统中“隐私-效用”权衡的结构性特征。该论文录用为ICML 2026 Position track的Regular论文。
该论文第一作者及通讯作者是厦门大学高级工程师范晓亮,并由硕士生陈嘉睿、刘卓栋、杨子棋、许培炫、沈瑞敏、刘俊辉、Jianzhong Qi教授(墨尔本大学)、王程教授共同合作完成。
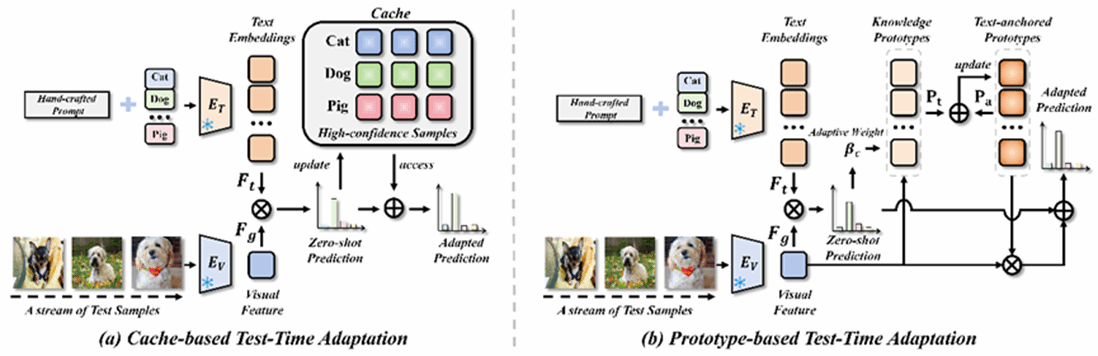
4.Prototype-Based Test-Time Adaptation of Vision-Language Models
测试时间适应(TTA)已成为视觉语言模型缓解预训练分布与测试数据分布差异的重要方法。近期研究主要关注基于缓存机制的无反向传播测试时间适应方法,但这类方法仍存在两个关键局限。首先,随着缓存规模或类别数量的增加,检索开销会带来额外的推理延迟,导致其在大规模应用场景中的效率受限。其次,当缓存中的样本数量不足,或其中包含错误预测样本时,模型容易受到噪声干扰,从而出现性能不稳定的问题。针对上述问题,本文提出了基于原型的测试时间适应方法(PTA)。与以往稀疏的实例级缓存机制不同,PTA采用更加紧凑的原型级知识累积方式,将历史测试样本中的有效信息整合到类别原型中,从而避免了缓存填充与检索带来的推理延迟和潜在信息损失,为视觉语言模型提供了一种更加高效、稳定且易于部署的测试时间适应方案。
该论文第一作者为厦门大学人工智能研究院2023级硕士生黄钊宏,通讯作者为纪荣嵘教授,由2022级博士研究生张玉鑫、2024级硕士研究生刘文婧、晁飞副教授共同合作完成。
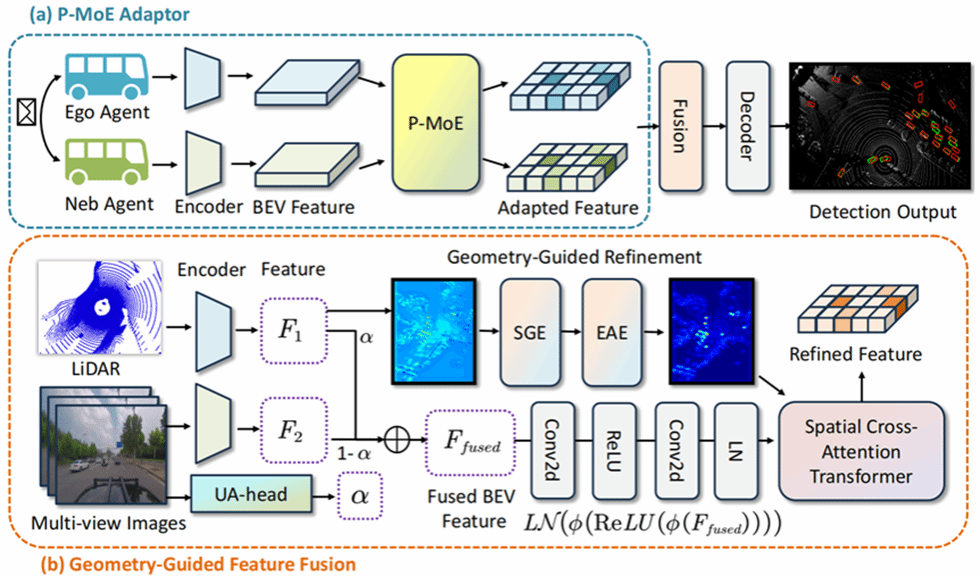
5.X-MoGe: A Cross-Modal Adaptation Framework with Mixture-of-Experts and Geometry Guidance for Heterogeneous Collaborative Perception
多智能体协同感知能够提升自动驾驶的感知范围与鲁棒性。通常不同智能体会搭载异构传感器且采用不同感知网络,引发严重的语义与几何位置不一致问题,进而影响多智能体间协同感知性能。由此,本文提出一种结合混合专家机制与几何引导融合的跨模态自适应异构协同感知框架X-MoGe。本文设计像素级混合专家模块(P-MoE),在异构感知条件下,对各模态独有的语义特征进行自适应建模;同时设计几何引导特征融合模块,引入显式几何先验约束,在鸟瞰图特征空间中实现特征的空间对齐与一致性约束。在OPV2V、DAIR-V2X 协同感知数据集上的实验结果表明所提方法的优异性能。
该论文第一作者是厦门大学2024级硕士生林文铠,通讯作者是温程璐教授,并由博士生刘智鸿共同完成。
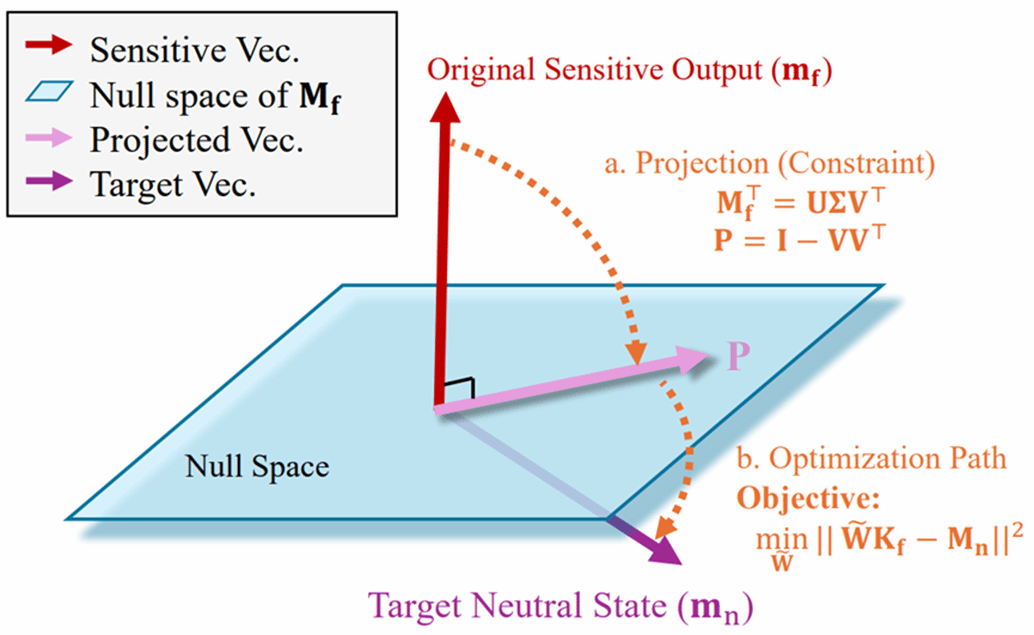
6.ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models
大模型在训练过程中会不可避免地记住一些敏感信息(比如隐私数据、有害知识)。因此需要知识遗忘(knowledge unlearning)。ZeroUnlearn将大模型中的知识遗忘问题重新表述为一种表示重映射问题:不是通过重新训练或梯度微调去删除数据,而是直接在模型内部将与待遗忘知识对应的表示映射到一个中性状态(如<EOS>),从而实现知识的覆盖与去除。具体而言,ZeroUnlearn通过构造带有正交约束的乘法参数更新,在少量样本条件下求解一个闭式解,使遗忘前后的表示相互正交,从而避免原有知识残留并减少对其他知识的干扰。相比传统基于微调的unlearning方法,ZeroUnlearn无需大规模训练,计算开销低,同时在保证遗忘效果的同时更好地维持模型整体性能,实现了unlearning效率与模型utility之间的良好平衡。
该论文共同第一作者是厦门大学信息学院2025级博士生林宇杰和2025级硕士生杨成义,通讯作者是苏劲松教授,由硕士生向至尚、宋伊萍副教授(国防科技大学)共同合作完成。
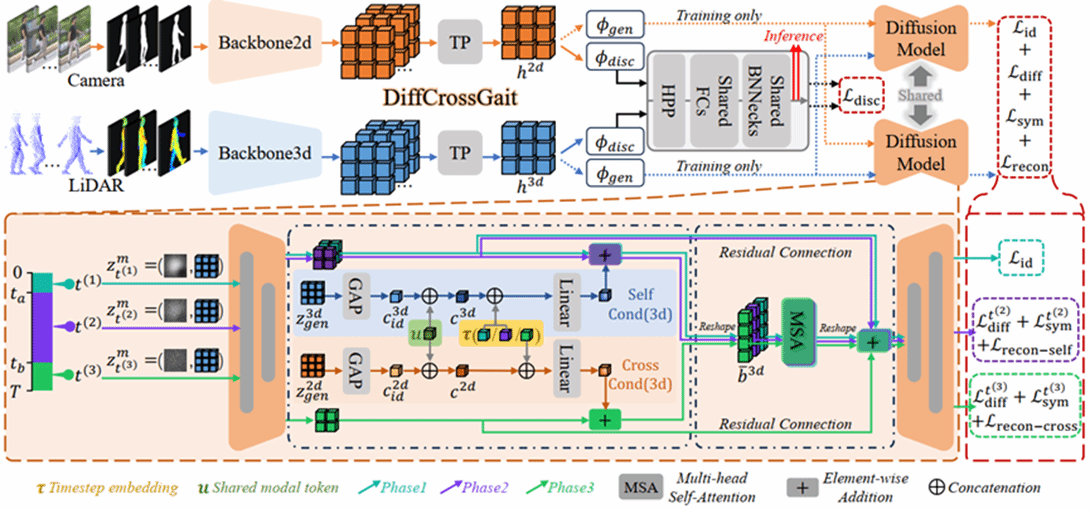
7.DiffCrossGait: Trajectory-Level Alignment for 2D-3D Cross-Modal Gait Recognition via Latent Diffusion
跨模态 2D–3D 步态识别长期受到模态差异的制约:2D 轮廓图与 3D 点云在数据分布、结构表达和动态特征上存在天然鸿沟。现有方法大多仅在最终特征嵌入层进行对齐,难以充分建模两种模态在生成与演化过程中的深层一致性。为此,本文提出 DiffCrossGait,一种基于统一潜在扩散过程的跨模态步态识别框架。不同于传统的末端特征对齐方法,DiffCrossGait 通过在潜在空间中引入共享高斯噪声,驱动 2D 与 3D 两种模态共同参与同一扩散演化过程,从而实现轨迹级别的连续对齐。进一步地,本文设计了三阶段对齐策略(Tri-Phase Alignment Strategy),利用不同噪声强度下的特征特性,分别约束身份锚定、动态一致性与跨模态结构可恢复性。该策略促使两种模态共享相似的去噪动态与信息瓶颈结构,从而学习更加稳定、鲁棒且模态无关的步态表征。值得说明的是,DiffCrossGait 将生成式对齐机制与判别式识别主干进行解耦。扩散模型仅作为训练阶段的优化目标使用,在推理阶段无需迭代去噪,因此不会引入额外计算开销,保证了高效的实际部署能力。在 SUSTech1K 与 FreeGait 两个基准数据集上的大量实验表明,DiffCrossGait 在跨模态 2D–3D 步态识别任务中取得了当前最优性能,充分验证了其有效性与先进性。
该论文第一作者是厦门大学2024级博士生陆志阳,通讯作者是程明教授。
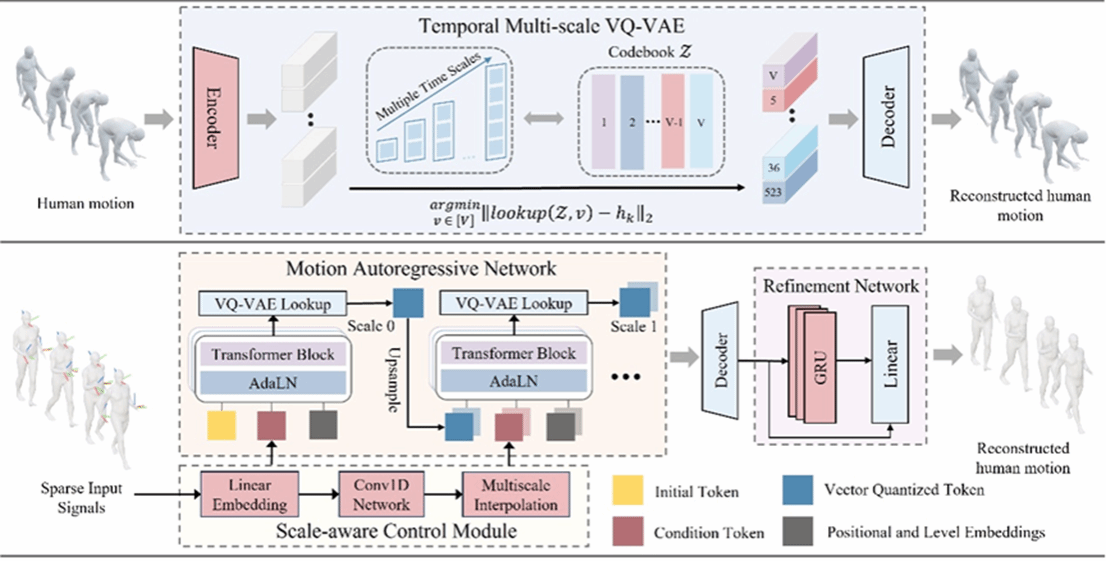
8.MotionMAR: Multi-scale Auto-Regressive Human Motion Reconstruction from Sparse Observations
人体运动遵循一种时间上的层级结构,从低频的全局轨迹延伸到高频的细节。受计算机视觉中多级自回归模型成功的启发,本文提出一种从稀疏观测中进行运动重建的由粗到细的框架MotionMAR。它首先估计人体运动的全局轨迹,然后逐步细化时间细节。该架构由四个集成组件组成:时间多尺度标记化(TMT)VQ-VAE 在多个时间分辨率上对数据进行编码,将语义运动与细微抖动分离开来;运动自回归网络(MAN)首先通过粗略索引建立全局结构,然后生成更精细的索引以恢复具体细节;尺度感知控制(SAC)模块整合稀疏跟踪数据,以确保生成的输出与实际观测一致;运动细化网络(MRN)平滑连续姿势并消除量化伪影。实验表明本方法在 AMASS 数据集上达到了最先进的准确率,为运动重建提供了一种可靠且结构感知的方法。
该论文第一作者是厦门大学2024级博士生罗裕华、2025级硕士生张俊圣,通讯作者是沈思淇长聘副教授,并由刘梦茵、林心成、颜明、陈朱迪、温程璐教授、许岚助理教授(上海科技大学)、王程教授共同合作完成。
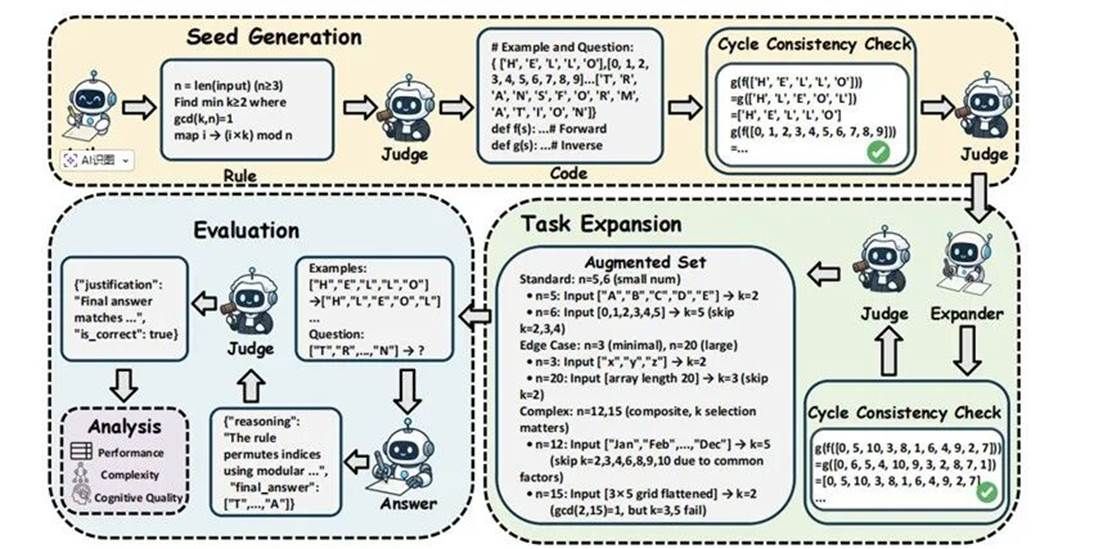
9.A²RBench: An Automatic Paradigm for Formally Verifiable Abstract Reasoning Benchmark Generation
抽象推理能力反映了大型语言模型(LLMs)提取和应用抽象规则的智能水平与泛化能力。然而,准确衡量该能力仍面临诸多挑战:现有的评测基准要么依赖高昂的人工标注成本从而限制了其规模,要么存在衡量“死记硬背”而非“真正推理”的风险。为解决这一问题,本文提出了一种名为 A²RBench 的自动化评测构建范式,涵盖生成、扩展、评估与分析四个阶段。具体而言,在生成阶段,LLMs 负责创建需要真正推理的多样化任务;在扩展阶段,LLMs 复用经过验证的规则并拓展新的输入空间以生成任务变体,从而实现基准的规模化。然而,该生成过程不可避免地会引发模型幻觉。为了消除幻觉,本文构建了一个理论框架,并证明了编程式验证——即测试逆向操作是否能完美还原正向操作(循环一致性)——能够保证任务解的唯一性。通过对主流 LLMs 进行广泛的评估,可得出以下结论:(1)当前 LLMs 在抽象推理方面存在根本性缺陷,顶尖模型在代表性子集上的表现远不及人类(39.8% vs. 68.5%);(2)当前 LLMs 在生成的 3D 任务复杂度上远不及 2D 和 1D 任务,暴露出其对高维任务缺乏深入理解;(3)具有更高信息复杂度的输入反而能够简化推理过程。
该论文第一作者是在厦门大学人工智能研究院2025级硕士生马晴川,通讯作者是郑侠武副教授,由2022级博士马跃萧、2025级硕士生谢天宇共同合作完成。
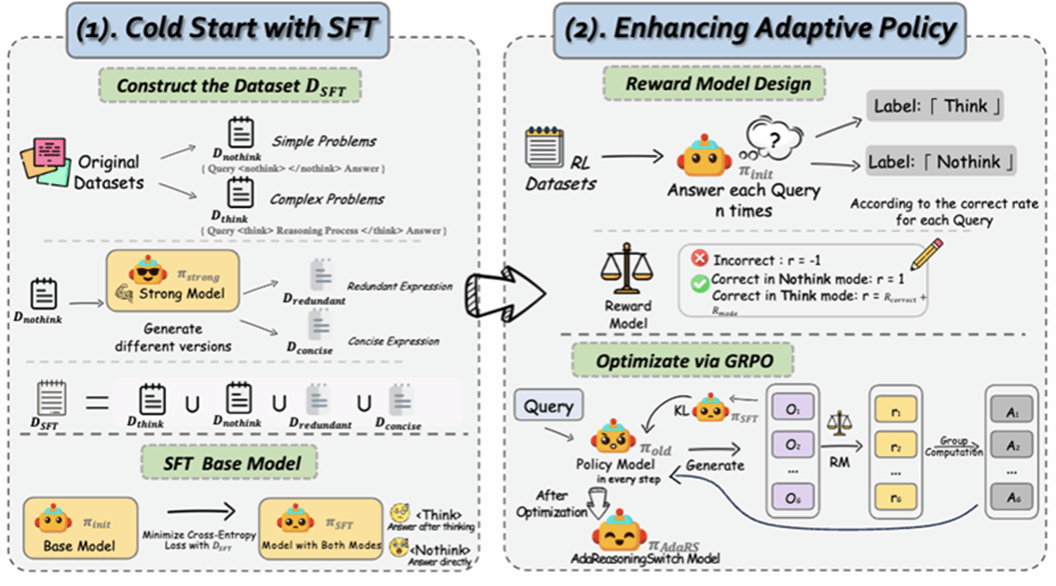
10. When Simple Problems Wear Complex Costumes: Improving Efficiency in LRM's Adaptive Reasoning
近期的大型推理模型(LRM)已展现出强大的多步问题求解能力,但普遍存在过度思考现象导致的效率低下问题:模型会对简单任务套用复杂推理流程,产生不必要的计算开销与推理延迟。虽然能够在显式推理生成和直接作答之间动态切换的自适应推理模型为该问题提供了潜在解决思路,但其效果存在明显缺陷:这类模型易被表面的语言复杂度误导,常常把表述冗长的简单问题误判为复杂问题。第一阶段采用增广数据进行有监督微调,使其学会忽略表层的语言繁冗特征。第二阶段基于分组相对策略优化(GRPO)算法,并设计自定义奖励函数开展强化学习,进一步优化模型的自适应决策策略。实验结果表明,该模型在不损失推理准确率的前提下有效降低了计算开销,同时对具有误导性的语言表述具备更强的鲁棒性。
该论文第一作者是厦门大学信息学院2024级硕士生任俊楠,通讯作者为张岩工程师,由陈骞(厦门海洋职业技术学院)、沈云航(腾讯优图)、李珂(腾讯优图)、张声传副教授、曹刘娟教授、纪荣嵘教授共同完成。
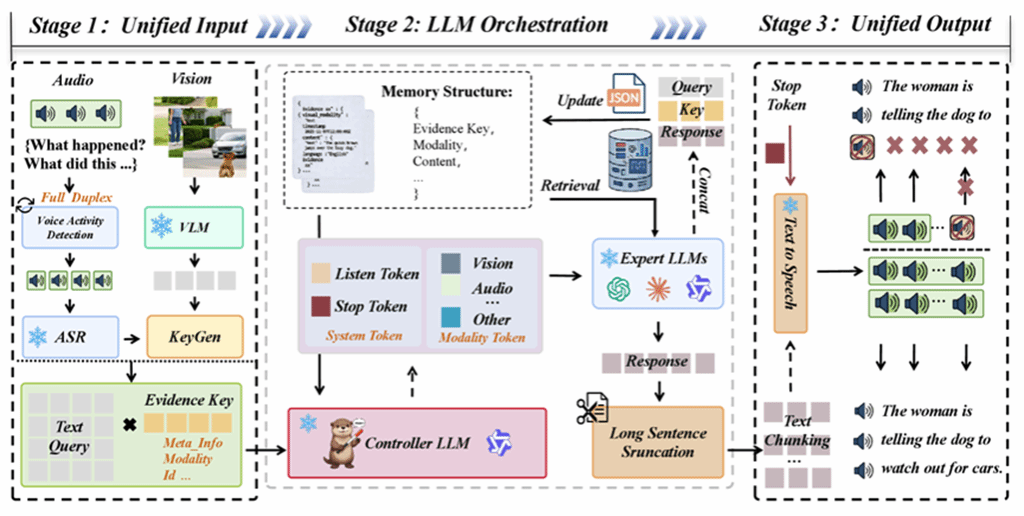
11. Training-Free Multimodal Large Language Model Orchestration
本文面向实时全模态助手构建中的高成本对齐、系统扩展困难和交互控制复杂等问题,提出了 Training-Free Multimodal Large Language Model Orchestration,一种训练免调优的多模态大语言模型编排框架。不同于依赖端到端多模态联合训练的方案,该方法通过现成大语言模型控制器、确定性路由器、外部模态专家、文本中心跨模态记忆和统一交互层,将图像/视频、音频/语音和文本能力整合到一个可控、可追踪、可扩展的多轮交互系统中。具体而言,系统利用闭集控制 token 完成专家选择与执行顺序控制,通过evidence-keyed memory 缓存并复用多模态专家输出,以减少重复专家调用,同时借助统一交互层支持流式输出、双工交互和用户打断场景下的任务取消。实验结果表明,该框架在多个多模态与全模态评测中取得了有竞争力的性能,并保持较低的编排开销和良好的模块化升级能力,为构建低成本、可维护的全模态智能助手提供了一种新的技术路径。
该论文第一作者是厦门大学人工智能研究院2025 级硕士生谢天宇,通讯作者是郑侠武副教授,由马跃萧、吴宇航、陈旺、纪家沂副教授、蔡达成教授(新加坡国立大学),纪荣嵘教授等共同合作完成。
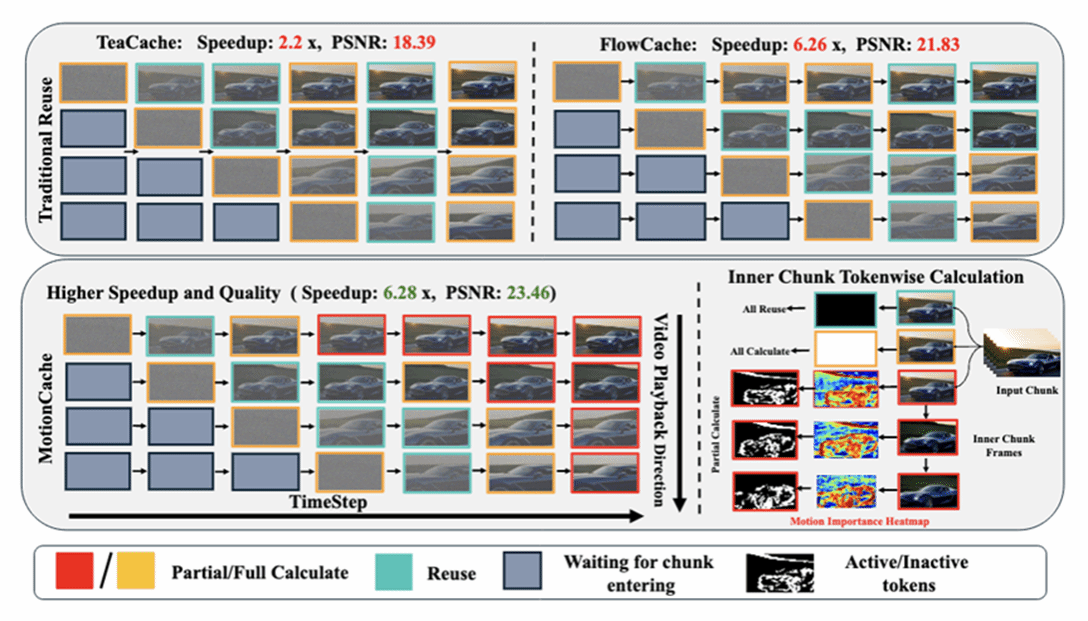
12. Motion-Aware Caching for Efficient Autoregressive Video Generation
本文提出了一种针对自回归视频生成的高效推理加速方法——MotionCache。现有自回归方法通常采用粗粒度缓存,直接复用整帧或整块 token,忽略了视频帧内部运动分布的不均匀性:动态区域需要频繁更新,而静态区域可以长期复用。MotionCache 利用帧间残差作为运动强度指标,通过动态token 重计算策略在静态与动态区域之间实现细粒度缓存更新,从而在保证生成质量的前提下显著降低计算量。论文进一步设计了粗到细推理策略,在全局结构保持稳定的同时,对高运动区域进行精细更新。理论分析表明,缓存误差与残差变化密切相关,而帧间差异能够有效估计残差上界。在不同自回归视频生成模型上的实验结果显示,MotionCache 可实现 1.64×–7.26×的推理加速,同时保持与原模型相当的视觉质量和时间一致性,为高效视频生成提供了一种可行方案。
该论文第一作者是厦门大学人工智能研究院2024级硕士生许靖,通讯作者是晁飞副教授。由2022级博士生马跃萧、刘松伟(字节跳动)、2025级硕士生郑旭哲、刘世伟(德国马普所)、颜晨倩(字节跳动)、郑侠武副教授、纪荣嵘教授、王星(字节跳动)共同完成。
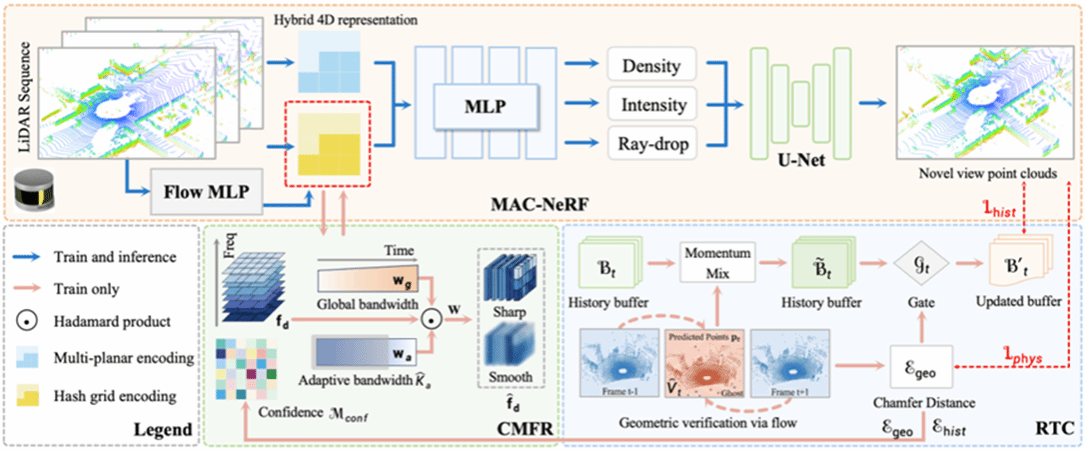
13. MAC-NeRF: Motion-Aware Curriculum Learning for Dynamic LiDAR NeRFs
激光雷达新视角合成技术通常受限于动态场景中的移动目标破坏了多视角一致性。已有的动态NeRF范式在面临不可靠的初始运动先验时,难以有效解耦真实几何结构与运动噪声,从而产生严重的监督冲突与重影伪影。本文提出一种基于运动感知课程学习的动态LiDAR NeRF高保真合成框架。提出的MAC-NeRF通过修正时间一致性模块(RTC)过滤错误的监督信号以优先学习可靠的时间对应关系,并构建置信度调制频率正则化机制(CMFR)自适应抑制早期伪影并平滑过渡到保留精细细节。对KITTI-360和nuScenes等大规模真实数据集的评估结果表明,该框架可显著提升复杂动态场景的几何渲染质量。
该论文第一作者是博士毕业生于尚书(东北大学),共同通讯作者是博士毕业生李文(布里斯托大学)、王程教授。并由博士生孙啸天、厍睿教授(北京航空航天大学)、汪汉云副教授(中山大学)、敖晟助理教授、温程璐教授共同完成。
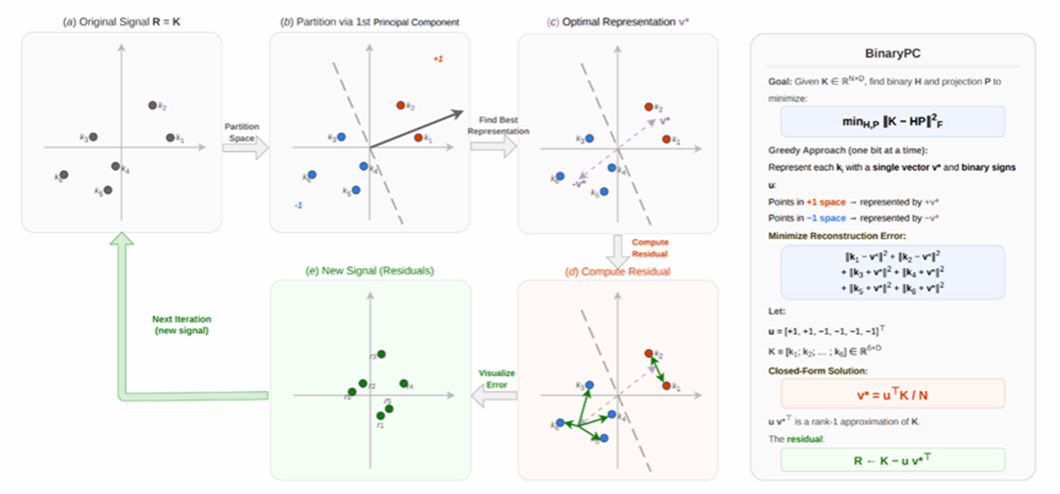
14. Training-Free Hashing-Based Attention via Binary Principal Components
长上下文大语言模型在多文档问答、对话智能体和复杂推理等场景中应用广泛,但解码阶段不断增长的 KV Cache 会带来显著的显存访问与计算开销,成为制约长序列推理效率的关键瓶颈。针对现有稀疏注意力方法容易造成精度下降、哈希式方法依赖随机投影或需要额外训练等问题,本文提出一种免训练、数据感知的哈希式稀疏注意力机制。该方法通过计算键向量的二值主成分,构造紧凑的 64-bit 二值哈希码及对应投影矩阵,在最小化重构误差的同时保留 KV 表征的结构信息;推理阶段利用 GPU 友好的位运算快速检索高相关token,并通过误差感知保护机制保留难以哈希的关键 token,从而兼顾检索精度与推理效率。实验结果表明该方法在接近全注意力精度的同时优于多种稀疏注意力和哈希基线,并在现代 GPU 上相较FlashAttention 实现最高 3.56×的端到端解码吞吐提升,为长上下文大模型高效推理提供了一种轻量、通用且可扩展的新方案。
该论文第一作者是厦门大学信息学院2024级硕士生余道海,通讯作者是曾展鹏助理教授,由陈科宇(腾讯优图)、2023级硕士生李文昊、沈志峰(腾讯优图),2024级硕士生林卢希、谯睿智(腾讯优图)、孙星(腾讯优图)、纪荣嵘教授共同合作完成。
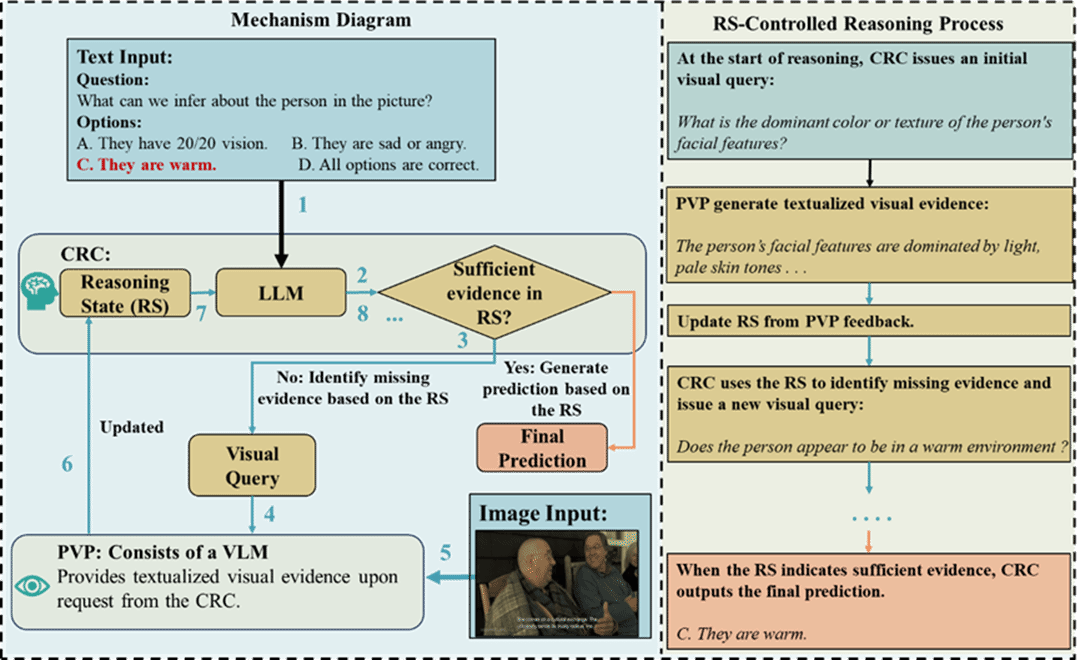
15. Look on Demand: A Cognitive Scheduling Framework for Visual Evidence Acquisition in Multimodal Reasoning
现有的多模态推理方法主要遵循两种范式:一种是在推理前将视觉信息转换为文本,另一种是在统一的视觉—语言空间中进行推理。前者通过静态文本化的方式压缩了细粒度视觉细节,而后者则受到语言主导性的影响,削弱了模型对视觉证据的忠实性。本文认为,一个核心挑战在于:视觉证据应当如何以及何时被引入推理过程。基于这一洞察,本文提出了一种多模态推理框架:由语言模型维护推理状态,并动态调度视觉证据的获取,决定何时查询独立的感知模块,以及何时终止推理。多个多模态推理基准上的实验结果表明,在零样本设置下,CSMR 在准确率上持续优于代表性基线方法。进一步分析表明,这些性能提升来源于由推理状态驱动的视觉查询机制和早停机制。
该论文第一作者是厦门大学人工智能研究院2025级博士生张阳,通讯作者是孙晓帅教授,由2025 级博士生赵瑞、2022 级硕士生孙武进、陈毅东教授、纪家沂副教授、陈骞(厦门海洋职业技术学院)、纪荣嵘教授合作完成。
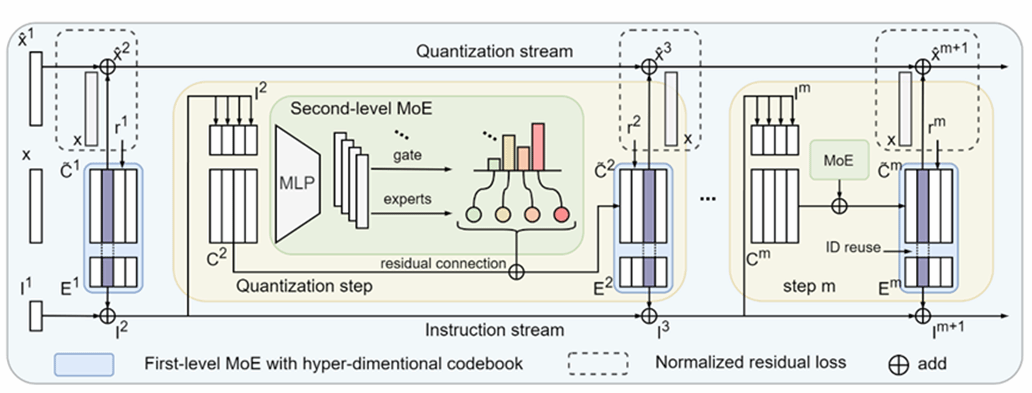
16. RQ-MoE: Residual Quantization via Mixture of Experts for Efficient Input-Dependent Vector Compression
论文针对高维向量压缩中表达能力不足与解码效率低之间的核心矛盾,指出传统量化方法依赖静态码本,难以适应复杂数据分布,而现有动态码本方法虽提升表达能力,却引入严格的串行依赖,导致推理效率受限。为此,本文提出一种名为 RQ-MoE的新型向量量化框架,通过引入混合专家机制实现输入相关的自适应压缩,同时兼顾高效并行解码能力。RQ-MoE 从结构上设计了双层 MoE + 双流量化机制:使码本能够根据输入动态调整,并将原本强依赖历史重建结果的串行过程转化为可并行执行的结构,从根本上消除了动态量化方法中的解码瓶颈。同时,本文提出基于残差比例归一化的NRL,有效缓解传统MSE在多阶段量化中对早期步骤过度关注、对后期优化不足的问题,提高训练稳定性与鲁棒性。实验结果表明,RQ-MoE在提高或保持重建精度与检索性能的同时,实现了解码加速。该框架能够更高效地利用码本有限的表示能力,且其并行解码特性在推荐系统、向量检索及生成模型等对延迟敏感的场景中具有重要应用价值。
该论文第一作者为厦门大学2024级硕士生钟政佳,通讯作者为李辉副教授。由2024级硕士生柯姝言、宋家奇、兰弘羿、2025级硕士生林在舟共同完成。
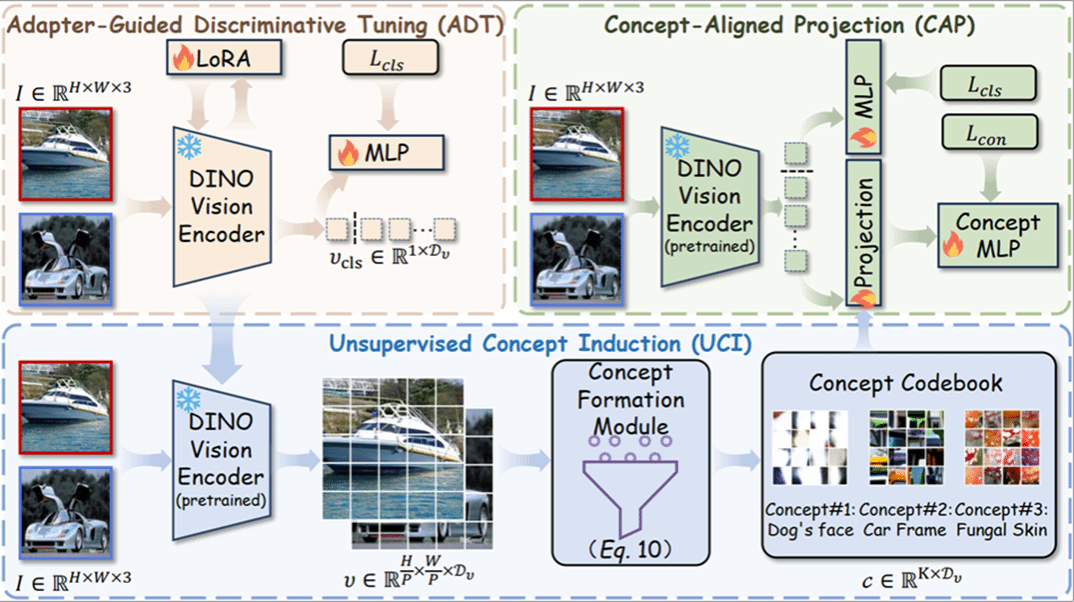
17. ForensicConcept: Transferable Forensic Concepts for AIGI Detection
生成式图像的快速发展显著提升了合成内容的真实感,但现有检测方法大多仍停留在黑盒判别式分类范式,难以解释模型依赖哪些伪造证据,也难以保证这些证据能迁移到未知生成器。针对这一问题,本文提出ForensicConcept,首次将显式法证概念引入 AI 生成图像检测。该方法先通过归因定位决策关键区域,再将这些局部证据聚类为紧凑的法证概念码本,并利用概念对齐预测生成可审计的证据读出;进一步以CleanDIFT扩散特征作为生成痕迹参考,通过CKNNA衡量检测证据与生成痕迹的对齐关系,并将扩散派生概念注入目标骨干网络以提升迁移能力。实验表明,该方法在GenImage、GAN-family与Chameleon上均取得稳定提升,为构建可解释、可迁移的下一代AI生成图像检测方法提供了新思路。
该论文共同第一作者是厦门大学信息学院2024级硕士生周门龑叔和人工智能研究院2023级硕士生周子寅,通讯作者是孙晓帅教授,由2021级博士生孙可、骆云鹏(腾讯优图)、纪家沂副教授以及纪荣嵘教授共同合作完成。